Step 1: Download Screaming Frog (The Free Version is Overpowered and Awesome)
That’s here.
I’m not, in general, a fan of browser tools for this kind of thing and the free version of Screaming Frog is so overpowered that anybody who does anything resembling webmaster or SEO work should have at least that. No that’s not an affiliate link, I just believe in the product that much.
Step 2: Configure The Screaming Frog Spider
This step is technically optional, but it allows you to crawl more pages and that’s what you’re hear for.
Once you’ve got Screaming Frog installed and up and running, go to Configuration > Spider:
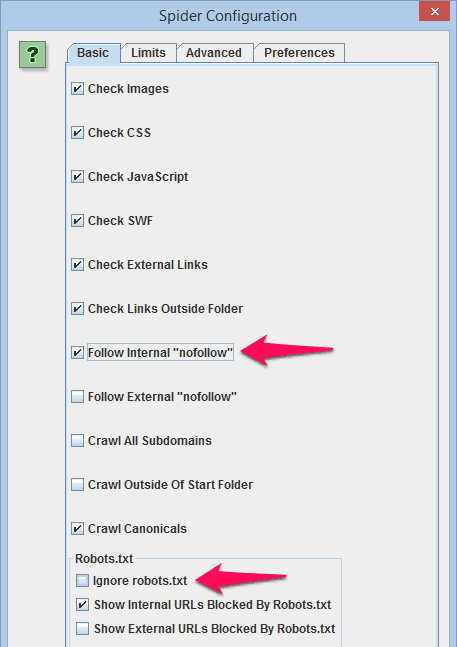
Leave everything else default, but check “Follow Internal ‘nofollow’” if you want to include the pages that are linked to with “nofollow” links. Even if these are nofollowed they could still get indexed by search engines. There’s another setting, “Ignore robots.txt” that you’ll need to think about. This allows you to scrape pages even if robots.txt blocks bots. While it’s not technically illegal to ignore robots.txt, it’s a pretty scuzzy thing to do and I would advise against it on anything but your own site:
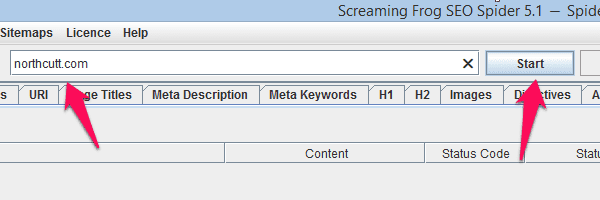
Step 3: Scan The Site
This is pretty self-explanatory. Type the name of the site into the text box up top, and hit “Start”, then wait for it to finish.
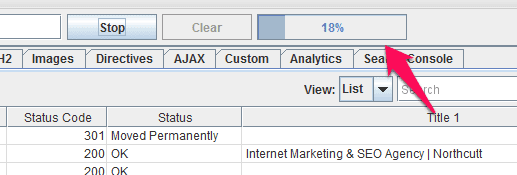
The progress bar next to the “Start” and “Clear” buttons will give you an estimate of how many of the pages have been crawled:
And you can find more detailed information in the bottom right hand corner:
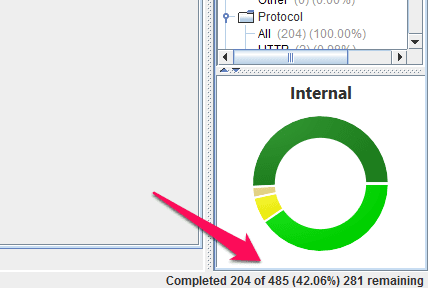
Keep in mind that these progress indicators are going to move backwards whenever they find links to new pages that weren’t previously known about.
Step 4: Narrow Down The List
Assuming that you’re hear for a list of the pages on the site, and not a bunch of images, javascript files, and what have you, now we need to whittle this down a bit. Stay in the “Internal” tab, go to the Filter dropdown menu, and select “HTML.”
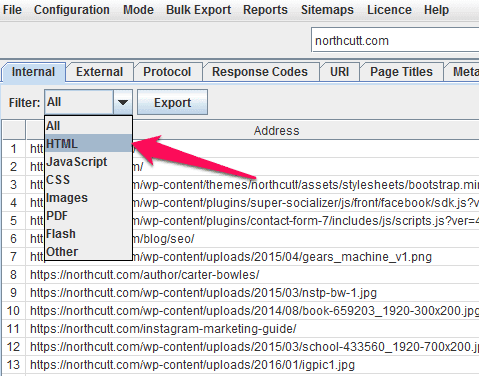
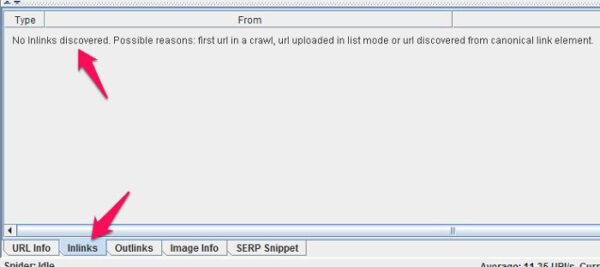
For the rest of this post, I’m going to assume that you are only interested in pages that are actually up on the site and running, but if you’re also interested in links to pages that redirect, 404 pages, etc., you already have everything you need…except, you need to be aware of something. If you were like me, and you didn’t type the exact, proper address for the homepage into the text box up top, you’re going to get a redirected page that isn’t necessarily linked to from anywhere else on the site:
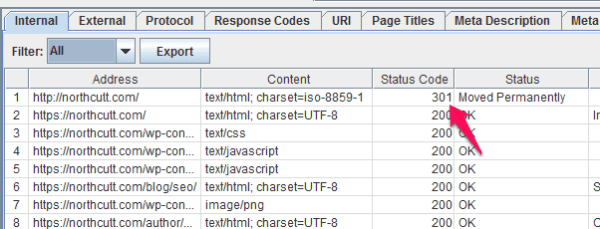
If you’re looking for 301s like this, you should click on this listing, then take a look at the bottom frame of the window, click the “Inlinks” tab, and take a look at what it says. If it says “No Inlinks discovered,” it means that there aren’t any pages on this site that link to that page, so the only reason it’s showing up is because you entered it.
Now, assuming you’re only interested in the live pages, this is how I do it. Start by sorting by status code:
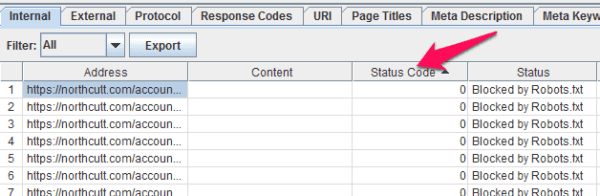
Then just scroll down until you get the the pages with Status Code 200, select them, copy them (ctrl+c), and paste them into your favorite spreadsheet program. You could also export the whole thing using Screaming Frog’s “bulk export,” but personally I prefer to select what I need and just copy it directly.
And that’s it!
Of course, now that you’ve gotten this far, you can probably see that you’ve got a lot more valuable information to work with than just a list of URLs. You can find duplicates, look for missing title tags and other markup, find issues in your site architecture, and a whole lot more.